Unionized Data Governance in Virtual Power Plants
Note: This post is a trimmed down version of a recent paper of the same name, written with Philippe Bonnet, Irina Shklovski, Laura Watts and Sebastian Büttrich. The full pdf is available on Arxiv.org
Introduction
Integrating renewable energy sources — such as wind, solar and tidal — into our electrical grid, is an essential component in the reduction of greenhouse gas emissions, but it also introduces several serious problems to power system operators. The main problem is that these sources are non-dispatchable, meaning that we cannot control their production. But the need for electricity (the “load”) is unaffected by this fluctuating supply. This creates large gaps in time between production and load, which is an issue as there is currently no viable solutions for large-scale energy storage.1 The electrical grid operators constantly balance the production and the consumption of energy in order to maintain a stable grid. So even if we generate enough renewable energy to match our demand on average, the need to balance consumption and non-dispatchable generation on a minute-to-minute basis is an on-going problem.
A proposed way to balance a grid with a large amount of non-dispatchable generation is to incorporate demand-side flexibility (Mohler and Sowder 2017). The load on the grid is constrained due to physical limits of the infrastructure, so flexibility, or supply-following load, eases this constraint by managing the electrical demand – making demand dispatchable to balance the uneven renewable generation and its storage. Temporary energy storage and other types of dynamic demand response are crucial to managing renewable energy flexibly on the grid.
But in order to achieve this flexibility, the future electricity networks, as envisioned by especially Taneja, Lutz, and Culler (2013) and Katz et al. (2011), will need to be digitally networked electrical grids that continuously coordinate and optimize operation through ICT systems (see also Bondy et al. 2015; M. M. He et al. 2008; Aman et al. 2015; Siano 2014). This data infrastructure is a layer on top of the electrical grid, transporting information about the state of both industrial and domestic demand and generation. It organizes flows of data concerning home and individual energy use. These flows of data can be used to make decisions on how to balance the grid or on how to store electricity: Data is Electricity!
The data infrastructure associated with the electricity system relies on personal data. For example, home usage data in a 1-hour resolution can disclose whether you are home (Liisberg et al. 2016), and sub-second resolution can reveal which movies you are watching (Greveler et al. 2012). Data governance is essential to manage the impact of such data infrastructures on society.
A proposed component of this flexibly-managed smart grid, is what has popularly been coined Virtual Power Plants2 (VPPs). A VPP provides flexibility by aggregating a host of smaller distributed energy resources (DERs) — such as solar panels, domestic batteries, electric vehicles or electric heating systems — using their combined capacity to provide services normally reserved for industrial scale power plants.
The subset of VPPs of interest for this paper, are those in which the DERs, or assets, are owned by individuals outside the organization that owns the VPP. The VPP as a concept includes all of the stakeholders, but we are particularly interested in relationship between the asset-owners and the aggregator. An asset-owner is a stakeholder that owns an individual asset in the portfolio of the aggregator. An example is a homeowner with a heat pump, electric car or domestic battery that can be remotely controlled. The aggregator3 is the stakeholder controlling the ICT system that collects data and controls the assets. The relationship between asset, aggregator and VPP is shown in Figure 1.
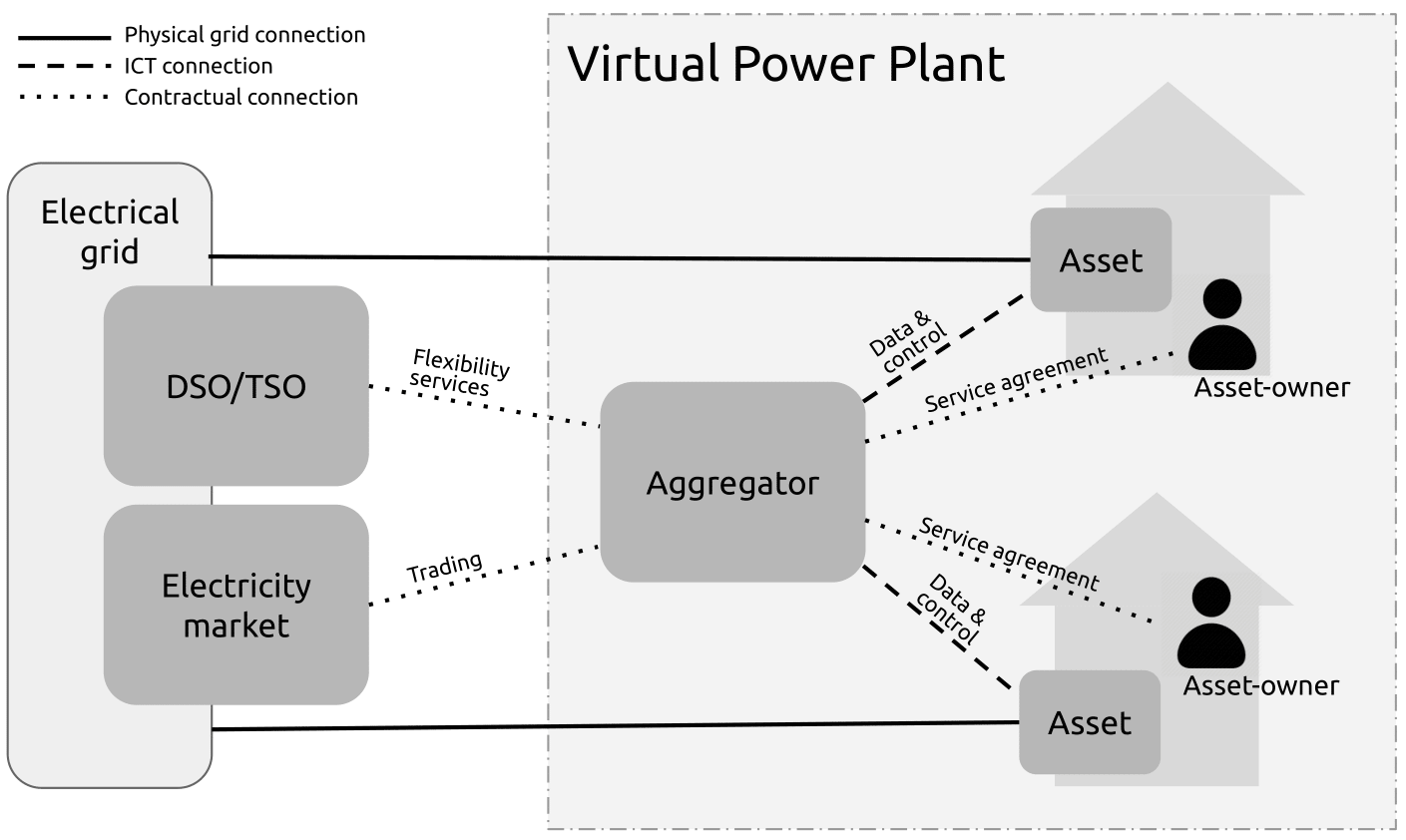
VPPs and Personal Data
The ICT system at the core of the VPP is dependent on several data flows in order to function. The most interesting and complex from a governance perspective is the flow from asset-owner to aggregator. This data flow contains electricity consumption information from the home (and potentially electric car), which is highly personal data. Behavior patterns can be inferred from electricity consumption, and the data acts as the basis for decisions made about the control of the asset, which influences both power cost and availability for the asset-owner. Because of the nature and purpose of this data, the data governance model employed within the VPP is crucial for the development of trust between asset-owners and aggregator.
The mass use of internet-connected services and devices that collect and store data of our use and behaviors have led to a continuous and pervasive monitoring of our lived lives. This data collection is generally not approved by the users, who find the data collection “creepy” (Shklovski et al. 2014). Still, despite regular public outcries, people continue to use the services, handing over their data. This has typically been described as an expression of the so-called “privacy paradox” (Norberg, Horne, and Horne 2007; Barnes 2006), which describes the discrepancy between intentions and behaviors when it comes to personal information disclosure.
Recent research suggest that this “paradox” represents wide-spread “digital resignation” (Draper and Turow 2019): People desire to control their personal information, but feel unable to do so, rendering them passive. A study on data leakage in mobile apps conducted in Shklovski et al. (2014) indicated that people were opposed to this practice of data collection, but could see no alternative except to stop using the smartphone as a smartphone altogether. The organizations collecting data benefit from this resignation, cultivating it through obfuscation measures, such as complicated privacy policies and transparency initiatives that allows partial access but not control (Draper and Turow 2019).
What differentiates the case of VPPs from data collection through mobile apps is in part the novelty of the domain. Continuos monitoring of electrical consumption is a new type of surveillance in a primary private sphere, the home, and unlike the phones and smart speakers we bring into the home ourselves, this monitoring becomes part of the infrastructure that makes the house. Finally, the aggregator has direct control of the home, controlling electricity availability and cost. The aggregator is not just sensing, but also actuating.
Data Flows and Asymmetrical Relations
A VPP can be viewed as a system that collects data from various sources and combines these in order to make decisions about the behavior of its assets and, by consequence, the lives of the asset-owners. In order to define the problem of data governance between the asset-owners and aggregator, we must first define the different types of data sources and flows within the system. From these we identify the relationships that these flows represent, and the problems to address.
Data Sources
For an aggregator to function within a VPP, the minimum data needed is the current status of the assets. In addition to this, the aggregator needs the privileges to remotely control the assets, which is tightly coupled to data access. Status data from a single asset, such as battery charge level or heat pump temperature, becomes richer when collected over time, and can be used to model the behavior of residents. These models can estimate when assets are idle or homes are vacant, which is highly relevant information for a VPP. But the richness of this data also makes it valuable for many purposes outside the scope of a VPP, such as profiling with the purpose of targeting or manipulation.
Data from assets alone does not allow for much meaningful decision-making. The crucial property of VPPs is the ability to optimize for outside parameters. For commercial aggregators, this data might come from electricity markets, detailing the market prices of electricity now or in the future, allowing the aggregator to optimize for price and profit by buying power in bulk when it is cheap (e.g Vayá and Andersson 2015; Bessa et al. 2012). Or it might come from DSOs, detailing bids for flexibility services in certain parts of the grid. For VPPs where profit is not the only goal, other relevant data sources might be the current generation of renewable energy, if the goal is to increase utilization of renewable energy, or the weather, if the goal is to stock up on energy in preparation for cold or extreme weather.
Data Flows
The data created at each source flows to the aggregator to be used in its decision engine, deciding where to increase or decrease electricity consumption. We can distinguish between two discrete types of data flows: The core flows, data which flows from the assets to the aggregator, and the supplementary flows, which is data from external sources used in the optimization algorithm of the aggregator (see Figure 2).
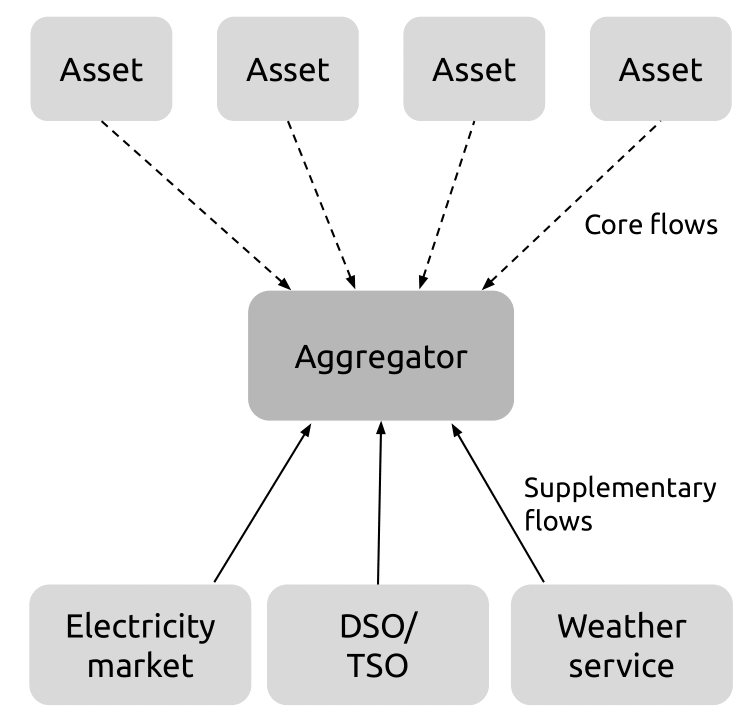
Figure 2: Data flows to the aggregator. The upper part represents the assets in the aggregators portfolio, while the lower part represents the data sources on which the aggregator bases its decisions.
Core Flows
The core flows are the basis of the capabilities of the VPP, carrying the current status, and thereby potential, of the portfolio. Each of the core flows represent the relationship between an organization (the aggregator) and an individual (the asset-owner). The core flows are numerous, a one-to-many relationship, and each of the core flows are in practice interchangeable. The aggregator simply needs enough capacity, it is less important exactly which assets that capacity is comprised of. If a core flow is discontinued or unavailable, the VPP can either continue with slightly decreased capacity or replace the flow with a similar asset.
Supplementary Flows
The supplementary flows are the basis of the direction of the VPP, carrying the current outside parameters to optimize for. The supplementary data flows have the characteristic in common that they are between two organizations. They are one-to-one relationships that are not interchangeable. Each supplementary flow contains data to be used in the optimization loop of the aggregators decision engine. If a supplementary data flow is discontinued or unavailable, the VPP might not be able to make decisions, rendering it idle.
Both categories of data flows, the core and supplementary flows, are necessary for the VPP to function. But due to the interchangeability, the individual core flow is of lower importance than the individual supplementary flow.
Vulnerability and Conflicting Goals
The nature of these data flows creates an asymmetrical power relation between the aggregator and the asset-owner. The aggregator has control over the electricity cost and availability for the asset-owners and access to valuable and personal data about them. This makes issues around data governance — how the data is used in the decision engine of the aggregator, and to what degree the personal data is analyzed and shared — important to the asset-owners. Simultaneously, the asset-owner is in a poor position to make demands or bargain with the aggregator, as the single data flow the asset-owner represents is not critical to the function of the VPP. The asset-owner has very limited leverage in such a negotiation.
This becomes an issue when the aggregator and asset-owners have conflicting goals. The workings of a system such as a VPP are a manifestation of its function or purpose (Meadows 2008), to borrow terms from systems theory, which can be seen as the high-level direction of the system. This direction is shaped by the structural properties of the system, the context it is placed in, and the goals of the stakeholders. Goals in this context represents properties of the desired direction of the system, and are unique for each stakeholder. Examples of goals for a VPP include maximizing profits, lowering prices for end-consumers, ensuring grid stability or transitioning to renewable energy. The goals of a stakeholder are often not explicitly stated and their internal compatibilities are complex. Goals A and B can be said to be “conflicting” if adjusting the direction of the system to address A negatively impacts B.
For example, the aggregator presumably has a goal of maximizing profits, and the asset-owners have a goal of preserving the integrity of their personal sphere. Given the issue of selling data about the behavior of asset-owners to third parties, these two goals are in conflict. However, the decision about whether to sell the data or not, is placed with the aggregator.
If an asset-owner wishes to alter the direction of the VPP, they are in a precarious position to do so. This is due to the asymmetry of political power and leverage, and the consequence of such a conflict: If the asset-owner stops the cooperation with an aggregator, the asset-owner loses all of the perks of the service, while the aggregator only loses a fraction of its capacity.
The Unionization Frame
The core data flows of a VPP can be seen as analogous to the relations of employment in classical capitalism, where the production is contingent on the pooling of a significant amount of labor. This labor is secured through individual contracts (or simply day-wages, meaning no contracts at all), which leaves the worker in an asymmetrical power relation to the employer, not unlike the relationship between asset-owner and aggregator.
The primary ways of addressing the asymmetry between worker and employer has been government regulations and the forming of trade unions. Trade unions mediate the flow of labor from workers to employer, and through this mediation gain leverage when negotiating wages and conditions. This is what is known as collective bargaining. Should the employer refuse to meet the demands of the trade union representing the workers, they can invoke a strike, removing the employers access to labor and thereby halting production.
In a more general sense, unions can be seen as aggregators of power. Whether in relation to labour, consumer rights, student conditions, or a host of other domains, the fundamental concept remains: By organizing, the interchangeability and replaceability of the individual relation is countered by collective action.
The main concepts from traditional trade unions can be used within a VPP as a way to obtain leverage and negotiating power in the relationship between aggregator and asset-owner. We propose the creation of a new institutional actor - the data union, which individual asset owners can join. The data union has clearly articulatedand defined goals and mediates on behalf of the asset owners, controlling all (or a significant amount of) the core data flows. This allows for collective bargaining, by using the possibility of halting or limiting the core flow (a “strike”) as leverage. The structure of unionized data flows is shown in Figure 3.
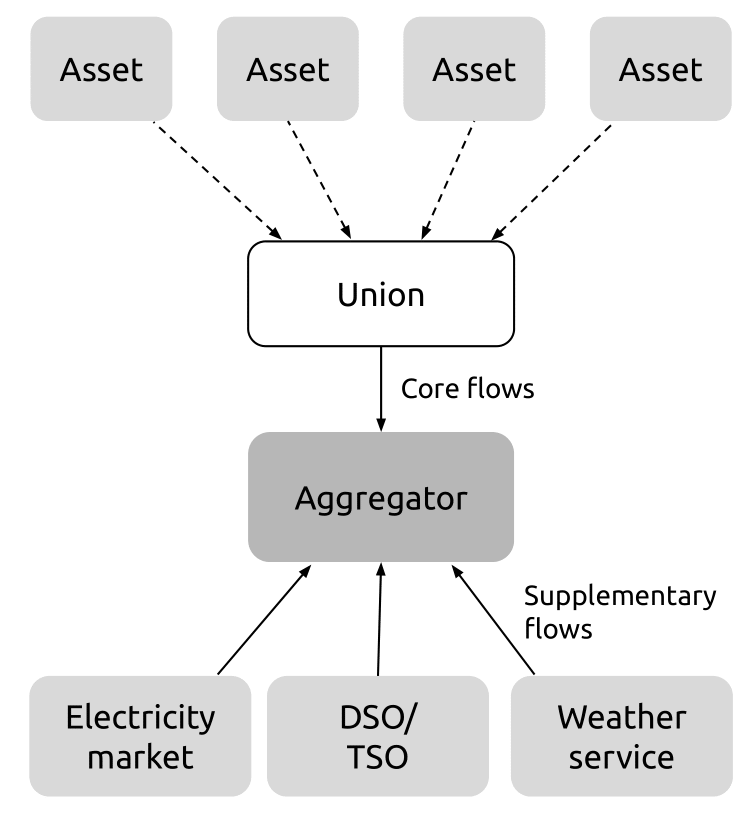
Figure 3: Unionized data flows to the aggregator. The core flows, the data from the assets, flows though a node of union-controlled infrastructure, allowing for leverage in negotiations with the aggregators
This mediation can be implemented in various ways, offering the union different degrees of power. The union could act like a traditional trade union, bargaining contract conditions on behalf on its members and, in case of a conflict, encouraging members to stop the data flow to the aggregator by turning of the connectivity of their collective assets. Since this union is interacting with an ICT system, there is also the possibility for much more direct and dynamic involvement of the union in the data flows. This could either be done by granting the union control over the assets in a way that trumps the aggregator, allowing them to dynamically start and stop the core flow. Alternatively the data flows could be rerouted to go through union-controlled infrastructure before being forwarded to the aggregator, creating a single point of control between the union and the aggregator.
If the union chooses to physically route the data through union-controlled infrastructure, this allows for a wider range of possibilities for control of data usage. One such possibility is anonymization through continuous de-identification. An aggregator needs to know which resources are available, but it does not strictly need to know which asset belongs to which asset-owner. By rehashing the identifiers of asset-owners at set intervals in time, the union can limit the aggregators ability to reason about the individual asset-owners behavioral patterns, while still allowing them access to all resource information. Controlling infrastructure also allows the union to construct a valuable dataset from which more general patterns and information can be deduced, something that has otherwise only been the privilege of the aggregator.
Enabling Productive Conflicts
Conflicts between stakeholders can be seen as a steering mechanism for a system, altering its direction according to the goals of those involved. But in order for this mechanism to work, these conflicts have to be productive. In order to enable productive conflicts, each side must acknowledge the power of the other. This creates an even foundation for the negotiations surrounding the conflict, taking into account the goals and interests of both sides.
In the case of digital resignation, conflicts become unproductive since the subjects see no possibility of influence. This stems from the organizations collecting data ignoring or obfuscating the power of the data subjects to a degree where the subjects do not perceive this power either. This phenomenon is beneficiary to the organization, as they receive little direct opposition to their goals.
By unionizing, the asset-owners can force the aggregator to acknowledge their power, leveraging their ability for collective action. This can be done by halting or manipulating the flows of data or electricity to and from the assets. And while these collective actions are not without costs for the asset-owners, the mere ability to disrupt the functionality of the aggregator increases leverage.
Principles for Data Governance
Based on the frame presented, we derive four principles of unionized data governance: (1) Collective bargaining, (2) representation in governing bodies, (3) disruptive measures and (4) strong accountability mechanisms.
To describe data governance models in general terms, we will use the framework proposed by Khatri & Brown, (Khatri and Brown 2010)4 partitioning the issues of governance into five decision domains: data principles, data quality, metadata, data access and data lifecycle. These domains influence each other, with the data principles informing the decisions and models in the remaining four domains. This relationship is visualized in Figure 4.

Figure 4: The five decision domains of data governance as defined in (Khatri and Brown 2010)
Unionization of Data Subjects
The basis for the following data governance principles, is the constitution of a data union that mediates the goals of the asset-owners.
By creating a union the asset-owners can engage in collective bargaining with the aggregator, negotiating the terms of the service that collects and processes information about their lives. The union replaces the one-to-many aggregator-to-asset-owner relationship with a one-to-one aggregator-to-union relationship. This gives the aggregator a single point of contact with the unionized asset-owners, and constitutes a single point of leverage, allowing asset-owners to make demands of the aggregator.
Data Principles and Representation
The decision domain of data principles is concerned with “clarifying the role of data as an asset”, its uses and purposes, and the communication of its uses. In other words, this is where the direction of all other decisions surrounding data governance is made. In the case of VPPs this includes whether selling or sharing data with third parties is part of the business model, whether modeling the behavior of individual assets should be allowed, which supplementary data sources the decision engine should be based on, and so on.
These principles should define a clear business owner of data assets, and a governing body should be constituted to oversee the approvement and enforcement of data usage in the context of the defined purpose and direction. One example of such a governing body is an “Enterprise Data Committee”. A committee of this sort would be an obvious place for union representation, allowing the interests and values of the asset-owners to be heard when discussing and reviewing data usage. It would provide an organizational frame where the union can impact the direction of the VPP by leveraging its control of the core data flow.
Disruptive Measures for Asserting Power
The data governance model should include concrete methods that allow for the asset-owners to disrupt the functioning of the VPP, if the current data usage does not live up to their demands. This could be done by limiting or halting the core flow of data, the VPPs basis for operation, thereby putting pressure on the aggregator to respond to their demands.
These measures are intended as a last resort, as none of the stakeholders are interested in a purely idle VPP. But its existence is important to establish the fact that the goals and demands of the asset-owners should be taken into account, in order to avoid damaging consequences for the aggregator.
This is in line with the Danish model for collective bargaining, where measures are taken to avoid disruptive conflicts such as a strike. This tradition is based on extensive negotiations towards a reconciliation that is acceptable to all parties. Only if the parties are unable to resolve the conflict, with government-assisted mediation, a strike is allowed. Still, these negotiations are always based on the fact that a strike is possible.
Accountability Needs Transparency
Khatri & Brown (2010) describe the “locus of accountability of decision making” in a decision domain to denote those held accountable if the handling of data does not live up to the data governance model. But before we can hold anybody accountable, we need to be able to assert that something has gone wrong.
The aggregator and asset-owners might have conflicting goals, but the aggregator is responsible for the majority of the data collection, storage, processing, and usage. This means that the aggregator does not necessarily have an interest in divulging information about actions that diverges from the data principles. Therefore the asset-owners must implement measures to ensure a high degree of transparency, enabling them to audit the actions of the aggregator.
From this we can see that transparency and auditing procedures around the implementation of the use of the data asset is crucial when designing a data governance model for VPPs.
Conclusion
In this article we have presented the frame of unionization, inspired by trade unions, as a way to describe the inherent problem of asymmetric relations of power in VPPs and its consequences for data governance models. We model the flows of data within a VPP as the core data flows from assets to the aggregator, and the supplementary data flows from external sources. The core flows are necessary for the VPP to function, while the supplementary flows provide context based on which the aggregator makes decisions.
For the aggregator, the individual assets are expendable and interchangeable, as long as the capacity is sufficient, much like a classical employer-worker relationship. By forming a union, the individual asset-owners are able to leverage their combined control over the assets to influence the data flow, processing and storage within the VPP.
From this frame we have derived a set of principles for data governance models within VPPs:
- Collective bargaining: The asset-owners should be able to bargain collectively about the conditions and purposes of the data flows. This includes which supplementary data flows to include and how to utilize them.
- Representation: The asset-owners should be represented in a central organizational governing body, which is in charge of defining and overseeing the data principles.
- Disruptive measures: The asset-owners should be able to limit or halt core data flow, allowing them to assert power and symmetry in the relation with the aggregator.
- Accountability: Transparency measures should be put in place to ensure the asset-owners ability to audit the data usage performed by the aggregator, in order to detect misuse and assign accountability
References
-
Adu-Kankam, Kankam O., and Luis M. Camarinha-Matos. 2018. “Towards Collaborative Virtual Power Plants: Trends and Convergence.” Sustainable Energy, Grids and Networks 16 (December): 217–30. doi:10.1016/j.segan.2018.08.003.
-
Aman, S., M. Frincu, C. Chelmis, M. Noor, Y. Simmhan, and V. K. Prasanna. 2015. “Prediction Models for Dynamic Demand Response: Requirements, Challenges, and Insights.” In 2015 IEEE International Conference on Smart Grid Communications (SmartGridComm), 338–43. doi:10.1109/SmartGridComm.2015.7436323.
-
Barnes, Susan B. 2006. “A Privacy Paradox: Social Networking in the United States.” First Monday, September. doi:10.5210/fm.v11i9.1394.
-
Bessa, R. J., M. A. Matos, F. J. Soares, and J. A. P. Lopes. 2012. “Optimized Bidding of a EV Aggregation Agent in the Electricity Market.” IEEE Transactions on Smart Grid 3 (1): 443–52. doi:10.1109/TSG.2011.2159632.
-
Bondy, Daniel Esteban Morales, Kai Heussen, Oliver Gehrke, and Anders Thavlov. 2015. “A Functional Reference Architecture for Aggregators.” In 2015 IEEE 20th Conference on Emerging Technologies Factory Automation (ETFA), 1–4. doi:10.1109/ETFA.2015.7301638.
-
Draper, Nora A, and Joseph Turow. 2019. “The Corporate Cultivation of Digital Resignation.” New Media & Society 21 (8): 1824–39. doi:10.1177⁄1461444819833331.
-
Greveler, Ulrich, Peter Glosekotter, Benjamin Justus, and Dennis Loehr. 2012. “Multimedia Content Identification Through Smart Meter Power Usage Profiles,” 8.
-
He, Mike M., Evan M. Reutzel, Xiaofan Jiang, Randy H. Katz, Seth R. Sanders, David E. Culler, and Ken Lutz. 2008. “An Architecture for Local Energy Generation, Distribution, and Sharing.” In 2008 IEEE Energy 2030 Conference, 1–6. doi:10.1109/ENERGY.2008.4781028.
-
Katz, Randy H., David E. Culler, Seth Sanders, Sara Alspaugh, Yanpei Chen, Stephen Dawson-Haggerty, Prabal Dutta, et al. 2011. “An Information-Centric Energy Infrastructure: The Berkeley View.” Sustainable Computing: Informatics and Systems 1 (1): 7–22. doi:10.1016/j.suscom.2010.10.001.
-
Khatri, Vijay, and Carol V. Brown. 2010. “Designing Data Governance.” Commun. ACM 53 (1): 148–52. doi:10.1145⁄1629175.1629210.
-
Liisberg, J., J. K. Møller, H. Bloem, J. Cipriano, G. Mor, and H. Madsen. 2016. “Hidden Markov Models for Indirect Classification of Occupant Behaviour.” Sustainable Cities and Society 27 (November): 83–98. doi:10.1016/j.scs.2016.07.001.
-
Meadows, Donella H. 2008. Thinking in Systems: A Primer. Edited by Diana Wright. White River Junction, Vt: Chelsea Green Publishing.
-
Mohler, David, and Daniel Sowder. 2017. “Chapter 23 - Energy Storage and the Need for Flexibility on the Grid.” In Renewable Energy Integration (Second Edition), edited by Lawrence E. Jones, 309–16. Boston: Academic Press. doi:10.1016/B978-0-12-809592-8.00023-8.
-
Norberg, Patricia A., Daniel R. Horne, and David A. Horne. 2007. “The Privacy Paradox: Personal Information Disclosure Intentions Versus Behaviors.” Journal of Consumer Affairs 41 (1): 100–126. doi:10.1111/j.1745-6606.2006.00070.x.
-
Shklovski, Irina, Scott D. Mainwaring, Halla Hrund Skúladóttir, and Höskuldur Borgthorsson. 2014. “Leakiness and Creepiness in App Space: Perceptions of Privacy and Mobile App Use.” In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 2347–56. CHI ’14. Toronto, Ontario, Canada: Association for Computing Machinery. doi:10.1145⁄2556288.2557421.
-
Siano, Pierluigi. 2014. “Demand Response and Smart Grids—A Survey.” Renewable and Sustainable Energy Reviews 30 (February): 461–78. doi:10.1016/j.rser.2013.10.022.
-
Taneja, Jay, Ken Lutz, and David Culler. 2013. “Flexible Loads in Future Energy Networks.” In Proceedings of the Fourth International Conference on Future Energy Systems, 285–86. E-Energy ’13. Berkeley, California, USA: ACM. doi:10.1145⁄2487166.2487209.
-
Vayá, M. González, and G. Andersson. 2015. “Optimal Bidding Strategy of a Plug-in Electric Vehicle Aggregator in Day-Ahead Electricity Markets Under Uncertainty.” IEEE Transactions on Power Systems 30 (5): 2375–85. doi:10.1109/TPWRS.2014.2363159.
-
Vesey, Andrew. 1997. “The Virtual Utility.” In The Virtual Utility: Accounting, Technology & Competitive Aspects of the Emerging Industry, edited by Shimon Awerbuch and Alistair Preston, 43–55. Topics in Regulatory Economics and Policy Series. Boston, MA: Springer US. doi:10.1007⁄978-1-4615-6167-5_3.
-
Weill, Peter, and Jeanne Ross. 2004. IT Governance: How Top Performers Manage IT Decision Rights for Superior Results. Boston, MA, USA: Harvard Business School Press.
- Pumped-storage hydroelectricity is the primary large-scale energy storage solution, but it needs specific natural features (such as reservoirs) to be applicable.↩
- First proposed in (Vesey 1997) as “virtual utilities”. VPPs are an emerging concept, and there is not complete consensus on the definition. See Adu-Kankam and Camarinha-Matos (2018) for a litterature review.↩
- The term “aggregator” is sometimes used as a synonym for VPP, which is again a sign that the dust has not completely settled around the terminology in this field.↩
- Adapted from the IT governance model presented in (Weill and Ross 2004)↩